Чтобы распознать текст, мы находим множество твердых (и бесплатных) программ, таких как FreeOCR. Оказывается, однако, что нам не нужно устанавливать какие-либо программы на компьютере — с помощью функций Google Диска и Google Документов мы можем выполнять распознавание браузера.

Благодаря сервисам Google мы можем полностью распознавать текст с помощью всего лишь нескольких щелчков мышью. Все делается автоматически, и это детская игра, и эффект практически идеальный. Давайте посмотрим, как распознать текст из PNG-изображения, PDF-файла или только отсканированного документа, сохраненного в графическом формате.
Распознавание текста на Google Диске
Конечно, для выполнения всех описанных ниже действий требуется бесплатная учетная запись Google, чтобы мы могли использовать сервис Google Диска, а также Документы Google.
Перейти на Google Диск
Перейдите на Google Диск и войдите в свою учетную запись. Теперь нам нужно загрузить изображение с отсканированным документом на наш диск в облаке. Для этого просто нажмите правой кнопкой мыши на нашем Диске Google и выберите «Загрузить файлы …». Мы также можем просто перетащить файл с помощью сканирования непосредственно в окно браузера с помощью метода перетаскивания.
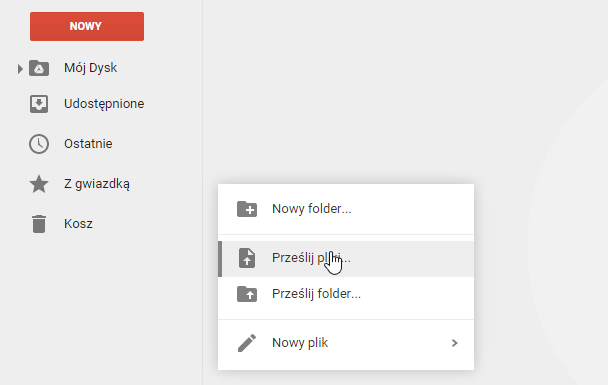
После того, как файл с нашим отсканированным документом был помещен в Google Диск, щелкните его правой кнопкой мыши, выберите «Открыть в …» и укажите в списке «Документы Google».
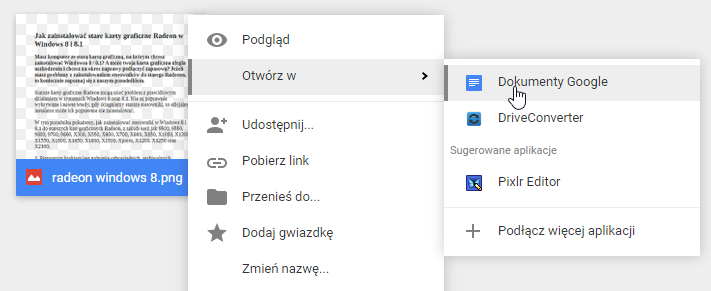
Наш графический файл с текстом теперь будет запущен в Документах Google, то есть в эквиваленте Google текстового процессора Word. Как только файл откроется, мы заметим, что на первой странице есть наше изображение с текстом — когда мы нажимаем на него, он будет окружен синим фреймом.
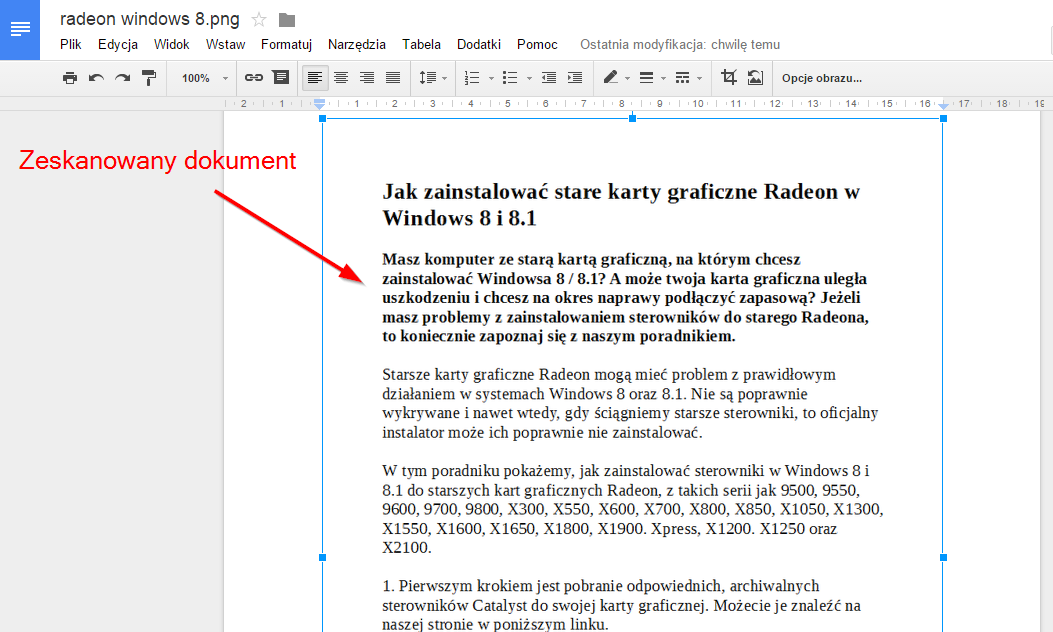
Однако нам больше не нужно выбирать. Когда мы прокручиваем страницу на следующую страницу, мы замечаем, что приложение Google Docs автоматически выполнило распознавание текста и содержит тот же контент в обычной, редактируемой форме. Все происходило автоматически, когда графический файл был открыт в Документах Google.
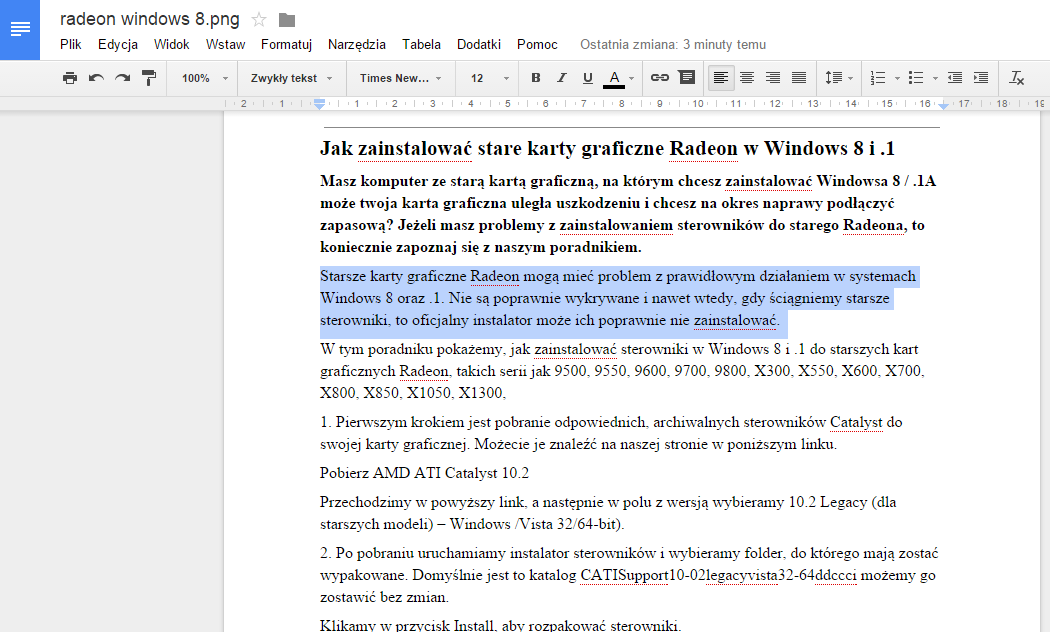
Теперь мы можем удалить изображение на первой странице (выберите и нажмите клавишу Delete), а затем в верхнем левом углу измените имя файла на более узнаваемый — мы можем, например, добавить имя OCR.
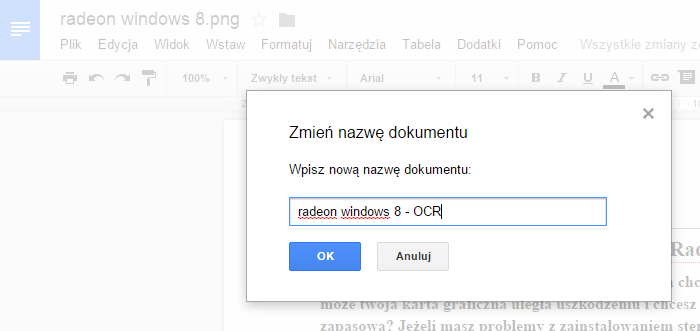
И это все — мы теперь читаем и преобразуем в редактируемую форму документа, который мы отсканировали. Мы можем оставить его на нашем Google Диске, отредактировать его в Документах Google или просто выбрать весь текст, скопировать его и вставить его в Word или Блокнот на компьютер, а затем сохранить на локальном диске.




